Jon Penney (2016)1 explored whether the widespread publicity about NSA/PRISM surveillance (i.e., the Snowden revelations) in June 2013 was associated with a sharp and sudden decrease in traffic to Wikipedia articles on topics that raise privacy concerns. This post tries to reproduce some of this findings.
Penney (2016) explored whether the widespread publicity about NSA/PRISM surveillance (i.e., the Snowden revelations) in June 2013 was associated with a sharp and sudden decrease in traffic to Wikipedia articles on topics that raise privacy concerns. If so, this change in behavior would be consistent with a chilling effect resulting from mass surveillance. The approach of Penney (2016) is sometimes called an interrupted time series design.
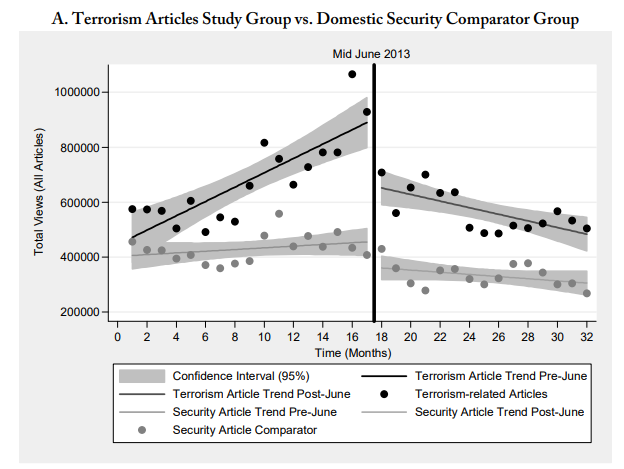
To choose the topic keywords, Penney referred to the list used by the US Department of Homeland Security for tracking and monitoring social media. The DHS list categorizes certain search terms into a range of issues, i.e., “Health Concern,” “Infrastructure Security,” and “Terrorism.” For the study group, Penney used the 48 keywords related to “Terrorism” (see appendix table 8). He then aggregated Wikipedia article view counts on a monthly basis for the corresponding 48 Wikipedia articles over a 32-month period from the beginning of January 2012 to the end of August 2014. To strengthen his argument, he also created several comparison groups by tracking article views on other topics.
Now, we are going to replicate and extend Penney (2016). All the raw data that you will need for this activity is available from Wikipedia (https://dumps.wikimedia.org/other/pagecounts-raw/). Or we can get it from the R-package wikipediatrend (Meissner and Team 2016).
Testing wikipediatrend package
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
library(tidyverse)library(wikipediatrend)library(lubridate)library(kableExtra)# download pageviews from R and Python languagestrend_data<-wp_trend(page=c("R_(programming_language)","Python_(programming_language)"),lang=c("en"),from=now()-years(2),to=now())# what we have?head(trend_data)%>%knitr::kable()%>%kable_styling(font_size=10)
language
article
date
views
732
en
python_(programming_language)
2019-11-15
7301
1
en
r_(programming_language)
2019-11-15
3052
733
en
python_(programming_language)
2019-11-16
4948
2
en
r_(programming_language)
2019-11-16
2279
734
en
python_(programming_language)
2019-11-17
5353
3
en
r_(programming_language)
2019-11-17
2259
1
2
3
4
5
6
7
8
9
# plotingtrend_data%>%ggplot(aes(x=date,y=views,color=article))+geom_line()+theme_light()+theme(legend.position="bottom")+ylim(0,25000)+labs(title="Daily Page Views",subtitle="Last 2 Years for articles of R and Python in english language")
Reproduction
Part A
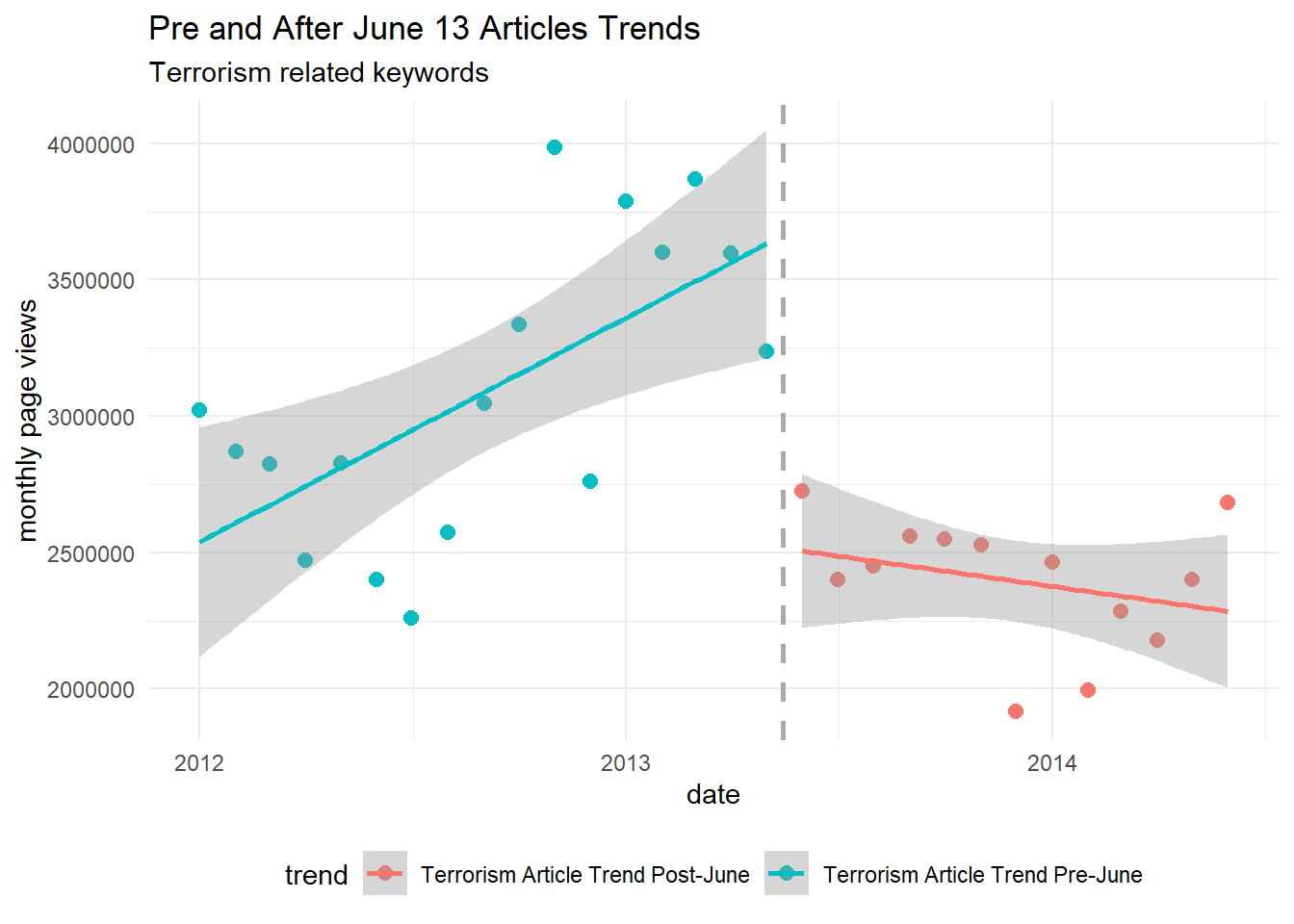
Read Penney (2016) and replicate his figure 2, which shows the page views for “Terrorism”-related pages before and after the Snowden revelations. Interpret the findings.
fig2
1
2
3
4
5
6
7
8
# loading DHS keywords listed as relating to “terrorism”keywords<-read.delim("./data/keywords_table8.txt")%>%janitor::clean_names()# lets see ithead(keywords)%>%knitr::kable()%>%kable_styling(font_size=11)
# getting wiki trends# we can call all keywords at once# but some keywords aren't return values, # so let's iterate over each one# making a "safe version", returning NULL instead of an errorsafe_wpTrend<-safely(wp_trend,otherwise=NULL,quiet=T)# for all keywordstrends<-keywords$wikipedia_articles%>%# extract from "url" the article namestr_extract("(?<=wiki/)(.*)")%>%# for each article, download the historic page viewsmap_df(function(.kw){# "...over a 32-month period from the beginning of January 2012 to the end of August 2014..."trends_resp<-safe_wpTrend(page=.kw,lang=c("en"),from="2012-01-01",to="2014-06-30"# removing last two months because they are returning 0 views)# will return NULL instreturn(trends_resp$result)})# "...aggregated Wikipedia article view counts on a monthly basis..."terrorism_articles<-trends%>%# remove some zeros from datafilter(views>0)%>%# group by "month" and sums the pageviewsmutate(date=floor_date(date,"month"))%>%group_by(date)%>%summarise(views=sum(views))%>%# mark the data related pre/pos Snowden revelations in June 2013mutate(trend=if_else(date<ymd("20130601"),"Terrorism Article Trend Pre-June","Terrorism Article Trend Post-June"))%>%ungroup()# Let's see the dataterrorism_articles%>%ggplot(aes(x=date,y=views,color=trend))+geom_point(size=2.5)+# ... the Snowden revelations in June 2013...geom_vline(xintercept=ymd("20130515"),color="dark grey",linetype="dashed",size=1)+geom_smooth(method="lm",formula=y~x)+theme_minimal()+theme(legend.position="bottom")+labs(title="Pre and After June 13 Articles Trends",subtitle="Terrorism related keywords",x="date",y="monthly page views")
Part B
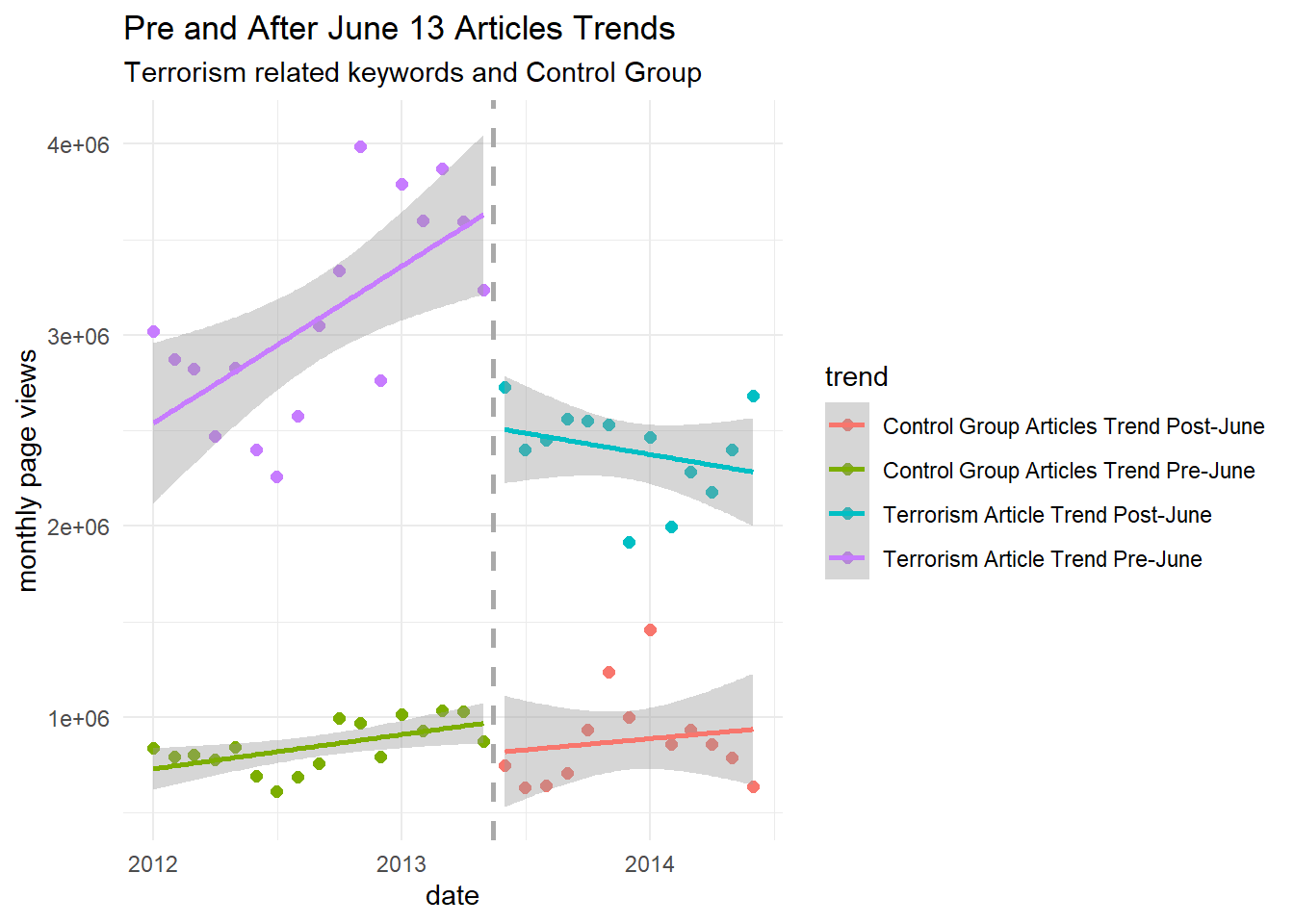
Next, replicate figure 4A, which compares the study group (“Terrorism”-related articles) with a comparator group using keywords categorized under “DHS & Other Agencies” from the DHS list (see appendix table 10 and footnote 139). Interpret the findings.
# get the trendscomp_trends<-comp_table$wikipedia_articles%>%str_extract("(?<=wiki/)(.*)")%>%str_to_lower()%>%map_df(function(.kw){# "...over a 32-month period from the beginning of January 2012 to the end of August 2014..."trends_resp<-safe_wpTrend(page=.kw,lang=c("en"),from="2012-01-01",to="2014-06-30")# will return NULL instreturn(trends_resp$result)})# "...aggregated Wikipedia article view counts on a monthly basis..."sec_articles<-comp_trends%>%filter(views>0)%>%mutate(date=floor_date(date,"month"))%>%group_by(date)%>%summarise(views=sum(views))%>%# ... the Snowden revelations in June 2013...mutate(trend=if_else(date<ymd("20130601"),"Control Group Articles Trend Pre-June","Control Group Articles Trend Post-June"))%>%ungroup()sec_articles%>%bind_rows(terrorism_articles)%>%ggplot(aes(x=date,y=views,color=trend))+geom_point(size=2)+geom_vline(xintercept=ymd("20130515"),color="dark grey",linetype="dashed",size=1)+geom_smooth(method="lm",formula=y~x)+theme_minimal()+theme(legend.position="right")+labs(title="Pre and After June 13 Articles Trends",subtitle="Terrorism related keywords and Control Group",x="date",y="monthly page views")
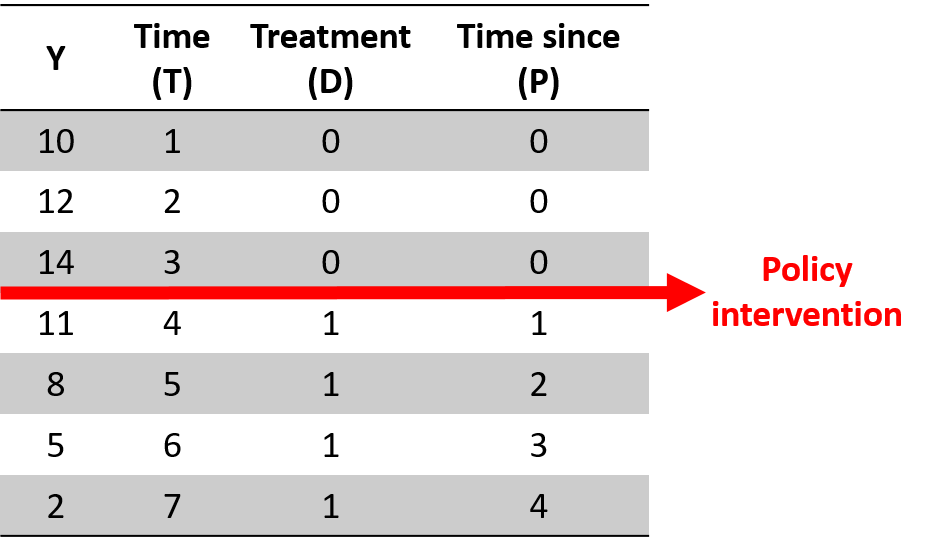
# building the dummy varsregr_data<-trends%>%# group trends by monthsfilter(views>0)%>%mutate(date=floor_date(date,unit="month"))%>%group_by(date)%>%summarise(views=sum(views))%>%ungroup()%>%arrange(date)%>%mutate(T=row_number(),# time varD=if_else(T<=18,0,1),# post-event data 18 is 2013-06-01P=if_else(T<=18,0,T-18)# post event time var)%>%rename(Y=views)# just to make equal to the model# what we haveregr_data%>%filter(T>14,T<=22)%>%knitr::kable()%>%kable_styling(font_size=11)
date
Y
T
D
P
2013-03-01
3868814
15
0
0
2013-04-01
3595489
16
0
0
2013-05-01
3235093
17
0
0
2013-06-01
2725519
18
0
0
2013-07-01
2399060
19
1
1
2013-08-01
2451065
20
1
2
2013-09-01
2559672
21
1
3
2013-10-01
2550031
22
1
4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# building the modelmod1<-lm(Y~T+D+P,data=regr_data)# let's seeregr_data%>%mutate(pred=predict(mod1))%>%ggplot(aes(x=date,color=D))+geom_point(aes(y=Y))+geom_line(aes(y=pred))+geom_vline(xintercept=ymd(20130615),linetype="dashed",size=1)+theme_minimal()+theme(legend.position="none")+labs(title="Pre and After June 13 Articles Trends",subtitle="Empirical Data and Model Prediction",x="Date",y="Monthly Page Views")
A time series are also subject to threats to internal validity, such as:
Another event occurred at the same time of the intervention and cause the immediate and sustained effect that we observe;
Selection processes, as only some individuals are affected by the policy intervention.
To address these issues, you can:
Use as a control a group that is not subject to the intervention (e.g., students who do not attend the well being class)
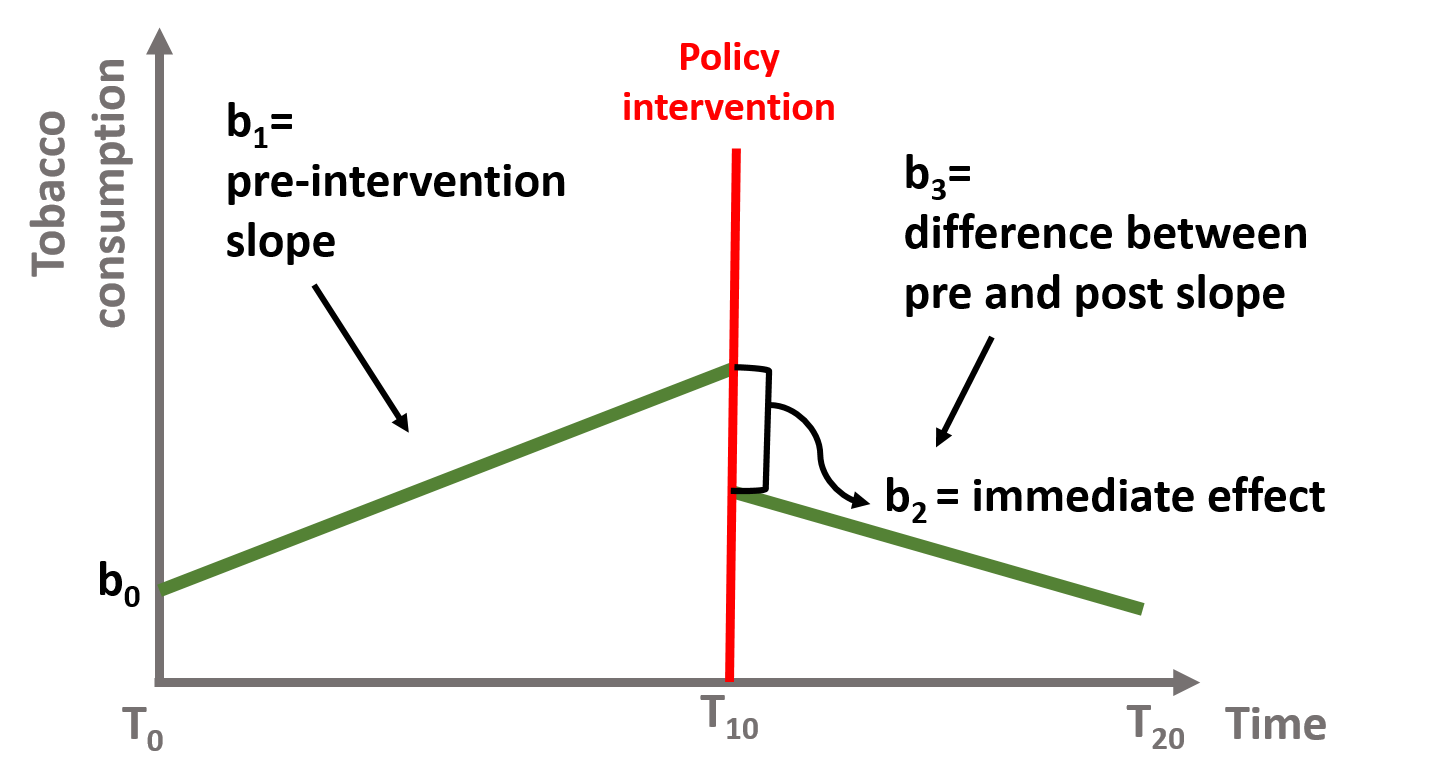
This design makes sure that the observed effect is the result of the policy intervention. The data will have two observations per each point in time and will include a dummy variable to differentiate the treatment (=1) and the control (=0). The model has a similar structure but (1) we will include a dummy variable that indicates the treatment and the control group and (2) we will interact the group dummy variable with all 3 time serie coefficients to see if there is a statistically significant difference across the 2 groups.
You can see this in the following equation, where $ G $ is a dummy indicating treatment and control group.
# building the dataset with control groupregr_control<-comp_trends%>%# summarise by monthlyfilter(views>0)%>%mutate(date=floor_date(date,unit="month"))%>%group_by(date)%>%summarise(views=sum(views))%>%ungroup()%>%mutate(T=row_number(),# Time var in monthsD=if_else(T<=18,0,1),# Mark Pre/Pos event data, 18 is 2013-06-01P=if_else(T<=18,0,T-18),# Time after the eventG=0# Control Group is 0)%>%rename(Y=views)%>%# add the effected data marked as treatment databind_rows(mutate(regr_data,G=1))# let's seeregr_control%>%filter(T>15,T<=21)%>%arrange(T,D,G,P)%>%knitr::kable()%>%kable_styling(font_size=11)
date
Y
T
D
P
G
2013-04-01
1032305
16
0
0
0
2013-04-01
3595489
16
0
0
1
2013-05-01
873192
17
0
0
0
2013-05-01
3235093
17
0
0
1
2013-06-01
747513
18
0
0
0
2013-06-01
2725519
18
0
0
1
2013-07-01
632677
19
1
1
0
2013-07-01
2399060
19
1
1
1
2013-08-01
641141
20
1
2
0
2013-08-01
2451065
20
1
2
1
2013-09-01
705947
21
1
3
0
2013-09-01
2559672
21
1
3
1
1
2
3
4
# lets fit the modelmod2<-lm(Y~T+D+P+G+G*T+G*D+G*P,data=regr_control)summary(mod2)
##
## Call:
## lm(formula = Y ~ T + D + P + G + G * T + G * D + G * P, data = regr_control)
##
## Residuals:
## Min 1Q Median 3Q Max
## -775138 -161714 28511 136682 842379
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 743019 151953 4.890 1.01e-05 ***
## T 10751 14038 0.766 0.44724
## D -86033 236027 -0.365 0.71696
## P -4588 29407 -0.156 0.87662
## G 1836297 214894 8.545 1.77e-11 ***
## T:G 40435 19853 2.037 0.04678 *
## D:G -992644 333792 -2.974 0.00445 **
## P:G -54965 41587 -1.322 0.19206
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 309000 on 52 degrees of freedom
## Multiple R-squared: 0.924, Adjusted R-squared: 0.9137
## F-statistic: 90.28 on 7 and 52 DF, p-value: < 2.2e-16
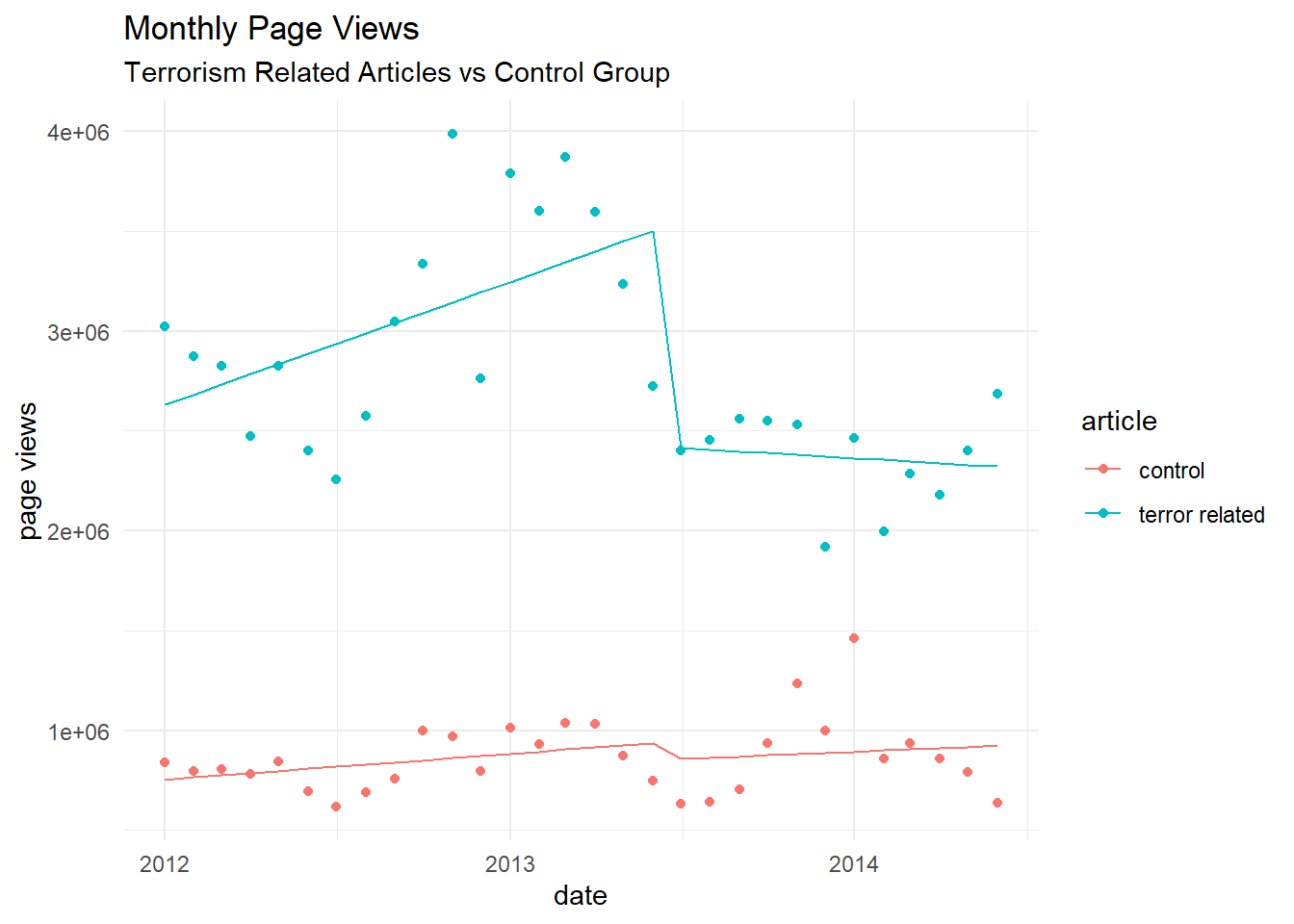
To interpret the coefficients you need to remember that the reference group is the treatment group (=1). The Group dummy $ b_{4} $ (coef $ G $) indicates the difference between the treatment and the control group. $ b_{5} $ (coef $ T:G $) represents the slope difference between the intervention and control group in the pre-intervention period. $ b_{6} $ (coef $ D:G $) represents the difference between the control and intervention group associated with the intervention. $ b_{7} $ (coef $ P:G $) represents the difference between the sustained effect of the control and intervention group after the intervention.
1
2
3
4
5
6
7
8
9
10
11
# can we see the points (trend and control) and the model fittedregr_control%>%mutate(pred=predict(mod2))%>%mutate(article=factor(G,labels=c("control","terror related")))%>%ggplot(aes(x=date,color=article,group=article))+geom_point(aes(y=Y))+geom_line(aes(y=pred))+labs(title="Monthly Page Views",subtitle="Terrorism Related Articles vs Control Group",y="page views")+theme_minimal()
Extra II
Finding Change Points in Time Series
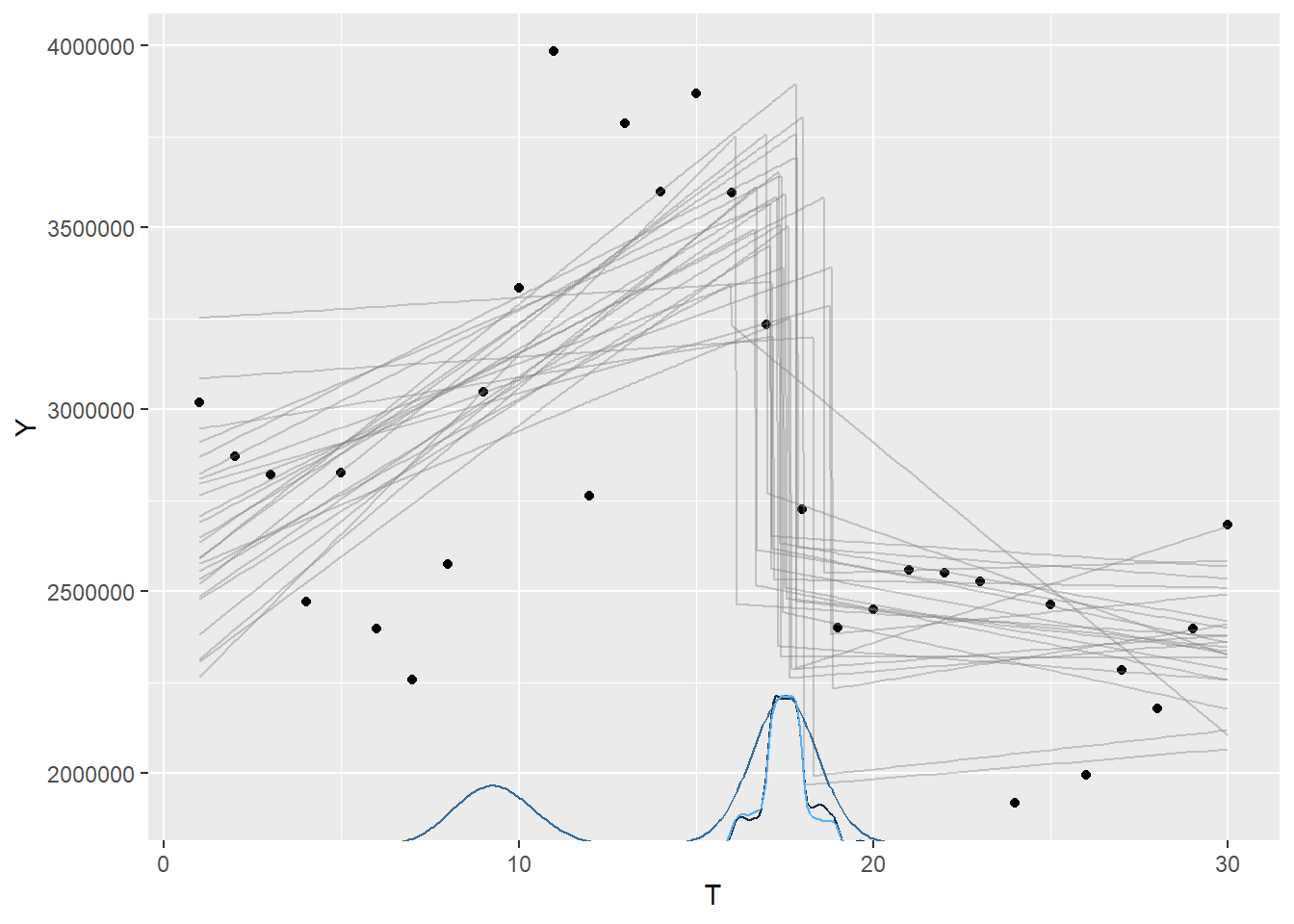
After these analysis I was thinking if is possible to find automatically a change points in time series. The Interrupted Time Series analysis assume a “change point” and check if the series, in fact, changes its behavior. How to check if this is a transition point indeed? As we know a linear regression made of arbitrary choice of points (interval in this case) can find false patterns.
library(mcp)# lets detect "two" linear trends# with interruption in the time seriesmodels<-list(Y~1+T,~1+T)# fit the modelsset.seed(42)fit_mcp<-mcp(models,data=regr_data,par_x="T")
That is cool, we can see that we detect a change point ( parameter $ cp_{1} $ ) around the 16o period, that is june, in your dataset. The model also show us the parameters fitted in each linear regression ( $ int $ for intercepts and $ T $ for slopes).